AVL-деревья
Falk0ner, вс, 06/07/2008 - 15:35.
Операция Peek в основном дублирует определение Pop с единственным важным исключением. Индекс top не уменьшается, оставляя стек нетронутым.
Реализация класса InorderIterator
Итерационный симметричный метод прохождения эмулирует рекурсивное сканирование с помощью стека адресов узлов. Начиная с корня, осуществляется спуск вдоль левых поддеревьев. По пути указатель каждого пройденного узла запоминается в стеке. Процесс останавливается на узле с нулевым левым указателем, который становится первым посещаемым узлом в симметричном сканировании. Спуск от узла t и запоминание адресов узлов в стеке выполняет метод GoFarLeft. Вызовом этого метода с t=root ищется первый посещаемый узел (рисунок 14).
// поместить элемент в стек
void Stack: : Push(const DataTypes item)
{
// если стек полный, завершить выполнение программы
if (top == MaxStackSize-1)
{
cerr << "Переполнение стека!" << endl;
exit(l);
}
// увеличить индекс top и копировать item в массив stacklist
top + +;
stacklist[top] = item;
}
void Stack: : Push(const DataTypes item)
{
// если стек полный, завершить выполнение программы
if (top == MaxStackSize-1)
{
cerr << "Переполнение стека!" << endl;
exit(l);
}
// увеличить индекс top и копировать item в массив stacklist
top + +;
stacklist[top] = item;
}
Операция Pop извлекает элемент из стека, копируя сначала значение из вершины стека в локальную переменную temp и затем увеличивая top на 1. Переменная temp становится возвращаемым значением. Попытка извлечь элемент из пустого стека приводит к сообщению об ошибке и завершению программы.
// взять элемент из стека
DataType Stack: : Pop(void)
DataType temp;
// стек пуст, завершить программу
if (top = = -1)
{
cerr << "Попытка обращения к пустому стеку! " << end.1;
exit(1);
}
// считать элемент в вершине стека
temp = stacklist[top];
// уменьшить top и возвратить значение из вершины стека
top - -;
return temp;
}
DataType Stack: : Pop(void)
DataType temp;
// стек пуст, завершить программу
if (top = = -1)
{
cerr << "Попытка обращения к пустому стеку! " << end.1;
exit(1);
}
// считать элемент в вершине стека
temp = stacklist[top];
// уменьшить top и возвратить значение из вершины стека
top - -;
return temp;
}
Операция Peek в основном дублирует определение Pop с единственным важным исключением. Индекс top не уменьшается, оставляя стек нетронутым.
// возвратить данные в вершине стека
DataType Stack: : Peek(void)const
{
// если стек пуст, завершить программу
if (top == -1)
{
cerr << "Попытка считать данные из пустого стека!" << end.1;
exit(l);
}
return stacklist[top];
}
DataType Stack: : Peek(void)const
{
// если стек пуст, завершить программу
if (top == -1)
{
cerr << "Попытка считать данные из пустого стека!" << end.1;
exit(l);
}
return stacklist[top];
}
Условия тестирования стека
Во время своего выполнения операции стека завершают программу при попытках клиента обращаться к стеку неправильно; например, когда мы пытаемся выполнить операцию Peek над пустым стеком. Для защиты целостности стека класс предусматривает операции тестирования состояния стека.
Функция StackEmpty проверяет, является ли top равным -1. Если — да, стек пуст и возвращаемое значение — TRUE; иначе возвращаемое значение — FALSE.
// тестирование стека на наличие в нем данных
int Stack: : StackEmpty(void)const
{
return top == -1;
}
int Stack: : StackEmpty(void)const
{
return top == -1;
}
Функция StackFull проверяет, равен ли top значению MaxStackSize - 1. Если так, то стек заполнен и возвращаемым значением будет TRUE; иначе, возвращаемое значение — FALSE.
// проверка, не переполнен ли стек
int Stack: : StackFuli(void)const
{
return top == MaxStackSize-1;
}
int Stack: : StackFuli(void)const
{
return top == MaxStackSize-1;
}
Метод ClearStack переустанавливает вершину стека на -1. Это восстанавливает начальное условие, определенное конструктором.
// удалить все элементы из стека
void Stack: : ClearStack(void)
{
top = -1;
}
void Stack: : ClearStack(void)
{
top = -1;
}
Стековые операции Push и Pop используют прямой доступ к вершине стека и не зависят от количества элементов в списке.
Абстрактный базовый класс Iterator
Класс Iterator позволяет абстрагироваться от тонкостей реализации алгоритма перебора, что дает независимость от деталей реализации базового класса. Мы определяем абстрактный класс Iterator как шаблон для итераторов списков общего вида.
Спецификация класса Iterator
Объявление
template < class T >
class Iterator
{
protected:
// Флаг, показывающий, достиг ли итератор конца списка.
// Должен поддерживаться производными классами.
int iterationComplete;
public:
// конструктор
Iterator(void);
// обязательные методы итератора
virtual void (void) = 0;
virtual void Reset(void) = 0;
// методы для выборки/модификации данных
virtual T Data(void) = 0;
// проверка конца списка
virtual int EndOfList(void) const;
};
class Iterator
{
protected:
// Флаг, показывающий, достиг ли итератор конца списка.
// Должен поддерживаться производными классами.
int iterationComplete;
public:
// конструктор
Iterator(void);
// обязательные методы итератора
virtual void (void) = 0;
virtual void Reset(void) = 0;
// методы для выборки/модификации данных
virtual T Data(void) = 0;
// проверка конца списка
virtual int EndOfList(void) const;
};
Обсуждение
Итератор является средством прохождения списка. Его основные методы: Reset (установка на первый элемент списка), (переход на следующий элемент), EndOfList (определение конца списка). Функция Data осуществляет доступ к данным текущего элемента списка.
Итератор симметричного метода прохождения
Симметричное прохождение бинарного дерева поиска, в процессе которого узлы посещаются в порядке возрастания их значений, является полезным инструментом.
Объявление
// итератор симметричного прохождения бинарного дерева.
// использует базовый класс Iterator
template < class T >
class InorderIterator: public Iterator < T >
{
private:
// поддерживать стек адресов узлов
Stack< TreeNode <T> * > S;
// корень дерева и текущий узел
TreeNode<T> *root, *current;
// сканирование левого поддерева используется функцией
TreeNode<T> *GoFarLeft(TreeNode<T> *t);
public:
// конструктор
InorderIterator(TreeNode<T> *tree);
// реализации базовых операций прохождения
virtual void (void);
virtual void Reset(void);
virtual T Data(void);
// назначение итератору нового дерева
void SetTree(TreeNode<T> *tree);
};
// использует базовый класс Iterator
template < class T >
class InorderIterator: public Iterator < T >
{
private:
// поддерживать стек адресов узлов
Stack< TreeNode <T> * > S;
// корень дерева и текущий узел
TreeNode<T> *root, *current;
// сканирование левого поддерева используется функцией
TreeNode<T> *GoFarLeft(TreeNode<T> *t);
public:
// конструктор
InorderIterator(TreeNode<T> *tree);
// реализации базовых операций прохождения
virtual void (void);
virtual void Reset(void);
virtual T Data(void);
// назначение итератору нового дерева
void SetTree(TreeNode<T> *tree);
};
Описание
Класс InorderIterator построен по общему для всех итераторов образцу. Метод EndOfList определен в базовом классе Iterator. Конструктор инициализирует базовый класс и с помощью GoFarLeft находит начальный узел сканирования.
Пример
TreeNode < int > * root; // бинарное дерево
InorderIterator treeiter(root); // присоединить итератор
// распечатать начальный узел сканирования.
// для смешанного прохождения это самый левый узел дерева
cout < < treeiter.Data();
// сканирование узлов и печать их значений
for (treeiter.Reset(); !treeiter.EndOfList(); treeiter.())
cout < < treeiter.Data() < < " ";
InorderIterator treeiter(root); // присоединить итератор
// распечатать начальный узел сканирования.
// для смешанного прохождения это самый левый узел дерева
cout < < treeiter.Data();
// сканирование узлов и печать их значений
for (treeiter.Reset(); !treeiter.EndOfList(); treeiter.())
cout < < treeiter.Data() < < " ";
Реализация класса InorderIterator
Итерационный симметричный метод прохождения эмулирует рекурсивное сканирование с помощью стека адресов узлов. Начиная с корня, осуществляется спуск вдоль левых поддеревьев. По пути указатель каждого пройденного узла запоминается в стеке. Процесс останавливается на узле с нулевым левым указателем, который становится первым посещаемым узлом в симметричном сканировании. Спуск от узла t и запоминание адресов узлов в стеке выполняет метод GoFarLeft. Вызовом этого метода с t=root ищется первый посещаемый узел (рисунок 14).
// вернуть адрес крайнего узла на левой ветви узла t.
// запомнить в стеке адреса всех пройденных узлов
template < class T >
TreeNode < T > * InorderIterator < T > : : GoFArLeft(TreeNode < T > * t)
{
// если t=NULL, вернуть NULL
if (t == NULL)
return NULL;
// пока не встретится узел с нулевым левым указателем,
// спускаться по левым ветвям, запоминая в стеке S
// адреса пройденных узлов. Возвратить указатель на этот узел
while (t->Left() != NULL)
{
S.Push(t);
t = t->Left();
}
return t;
}
// запомнить в стеке адреса всех пройденных узлов
template < class T >
TreeNode < T > * InorderIterator < T > : : GoFArLeft(TreeNode < T > * t)
{
// если t=NULL, вернуть NULL
if (t == NULL)
return NULL;
// пока не встретится узел с нулевым левым указателем,
// спускаться по левым ветвям, запоминая в стеке S
// адреса пройденных узлов. Возвратить указатель на этот узел
while (t->Left() != NULL)
{
S.Push(t);
t = t->Left();
}
return t;
}
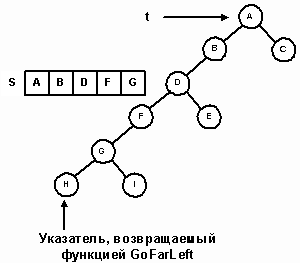 Рис. 14.
После инициализации базового класса конструктор присваивает элементу данных root адрес корня бинарного дерева поиска. Узел для начала симметричного сканирования получается в результате вызова функции GoFarLeft с root в качестве параметра. Это значение запоминается в переменной сurrent.
Рис. 14.
После инициализации базового класса конструктор присваивает элементу данных root адрес корня бинарного дерева поиска. Узел для начала симметричного сканирования получается в результате вызова функции GoFarLeft с root в качестве параметра. Это значение запоминается в переменной сurrent.
// инициализировать флаг iterationComplete. Базовый класс сбрасывает его, но
// дерево может быть пустым. начальный узлел сканирования - крайний слева узел.
template < class T >
InorderIterator < T > : : InorderIterator(TreeNode < T > * tree):
Iterator < T > (), root(tree)
{
iterationComplete = (root == NULL);
current = GoFarLeft(root);
}
// дерево может быть пустым. начальный узлел сканирования - крайний слева узел.
template < class T >
InorderIterator < T > : : InorderIterator(TreeNode < T > * tree):
Iterator < T > (), root(tree)
{
iterationComplete = (root == NULL);
current = GoFarLeft(root);
}
Метод Reset по существу является таким же, как и конструктор, за исключением того, что он очищает стек.
Перед первым обращением к указатель current уже указывает на первый узел симметричного сканирования. Метод работает по следующему алгоритму.1.Если правая ветвь узла не пуста, перейти к его правому сыну и осуществить спуск по левым ветвям до узла с нулевым левым указателем, попутно запоминая в стеке адреса пройденных узлов. 1.Если правая ветвь узла пуста, то сканирование его левой ветви, самого узла и его правой ветви завершено. Адрес следующего узла, подлежащего обработке, находится в стеке. Если стек не пуст, удалить следующий узел. Если же стек пуст, то все узлы обработаны и сканирование завершено.
Итерационное прохождение дерева, состоящего из пяти узлов, изображено на рисунке 15.
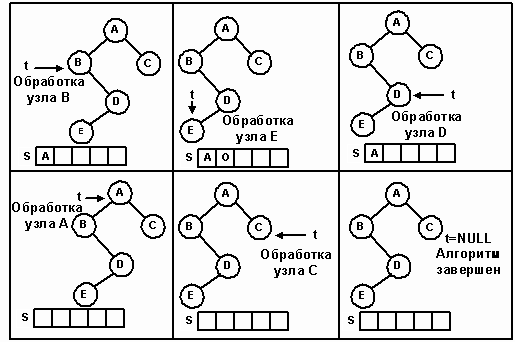 Рис. 15.
Рис. 15.
template < class T >
void InorderIterator < T > : : (void)
{
// ошибка, если все узлы уже посещались
if (iterationComplete)
{
cerr << ": итератор прошел конец списка!" << endl;
exit(1);
}
// current - текущий обрабатываемый узел.
// если есть правое поддерево, спуститься до конца по его левой ветви,
// попутно запоминая в стеке адреса пройденных узлов
if (current - > Right()! = NULL)
current = GoFarLeft(current - > Right());
// правого поддерева нет, но в стеке есть другие узлы,
// подлежащие обработке. вытолкнуть из стека новый текущий адрес,
// продвинуться вверх по дереву
else if (!S.StackEmpty())
current = S.Pop();
// нет ни правого поддерева, ни узлов в стеке. сканирование завершено
else
iterationComplete = 1;
}
void InorderIterator < T > : : (void)
{
// ошибка, если все узлы уже посещались
if (iterationComplete)
{
cerr << ": итератор прошел конец списка!" << endl;
exit(1);
}
// current - текущий обрабатываемый узел.
// если есть правое поддерево, спуститься до конца по его левой ветви,
// попутно запоминая в стеке адреса пройденных узлов
if (current - > Right()! = NULL)
current = GoFarLeft(current - > Right());
// правого поддерева нет, но в стеке есть другие узлы,
// подлежащие обработке. вытолкнуть из стека новый текущий адрес,
// продвинуться вверх по дереву
else if (!S.StackEmpty())
current = S.Pop();
// нет ни правого поддерева, ни узлов в стеке. сканирование завершено
else
iterationComplete = 1;
}
Алгоритм TreeSort
Когда объект типа InorderIterator осуществляет прохождение дерева поиска, узлы проходятся в сортированном порядке и, следовательно, можно построить еще один алгоритм сортировки, называемый TreeSort. Этот алгоритм предполагает, что элементы изначально хранятся в массиве. Поисковое дерево служит фильтром, куда элементы массива копируются в соответствии с алгоритмом вставки в бинарное дерево поиска. Осуществляя симметричное прохождение этого дерева и записывая элементы снова в массив, мы получаем в результате отсортированный список. На рисунке 16 показана сортировка 8-элементного массива.
#0include "bstree.h"
#0include "treeiter.h"
// использование бинарного дерева поиска для сортировки массива
template < class T >
void TreeSort(T arr[], int n)
{
// бинарное дерево поиска, в которое копируется массив
BinSTree<T> sortTree;
int i;
// вставить каждый элемент массива в поисковое дерево
for (i=0; i<n; i++)
sortTree.Insert(arr[i]);
// объявить итератор симметричного прохождения для sortTree
InorderIterator<T> treeSortIter(sortTree.GetRoot());
// выполнить симметричное прохождение дерева.
// скопировать каждый элемент снова в массив
i = 0;
while (!treeSortIter.EndOfList())
{
arr[i++] = treeSortIter.Data();
treeSortIter.();
}
}
#0include "treeiter.h"
// использование бинарного дерева поиска для сортировки массива
template < class T >
void TreeSort(T arr[], int n)
{
// бинарное дерево поиска, в которое копируется массив
BinSTree<T> sortTree;
int i;
// вставить каждый элемент массива в поисковое дерево
for (i=0; i<n; i++)
sortTree.Insert(arr[i]);
// объявить итератор симметричного прохождения для sortTree
InorderIterator<T> treeSortIter(sortTree.GetRoot());
// выполнить симметричное прохождение дерева.
// скопировать каждый элемент снова в массив
i = 0;
while (!treeSortIter.EndOfList())
{
arr[i++] = treeSortIter.Data();
treeSortIter.();
}
}
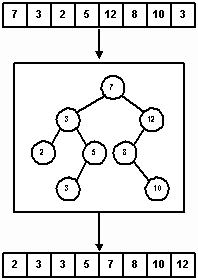 Рис. 16.
Эффективность сортировки вставкой в дерево.
Ожидаемое число сравнений, необходимых для вставки узла в бинарное дерево поиска, равно O(log2n). Поскольку в дерево вставляется n элементов, средняя эффективность должна быть O(n log2n). Однако в худшем случае, когда исходный список отсортирован в обратном порядке, она составит O(n2). Соответствующее дерево поиска вырождается в связанный список. Покажем, что худший случай требует O(n2) сравнений. Первая вставка требует 0 сравнений. Вторая вставка – двух сравнений (одно с корнем и одно для определения того, в какое поддерево следует вставлять данное значение). Третья вставка требует трех сравнений, 4-я четырех,..., n-я вставка требует n сравнений. Тогда общее число сравнений равно:
0 + 2 + 3 + ... + n = (1 + 2 + 3 + ... + n) - 1 = n(n + 1) / 2 - 1 = O(n2)
Для каждого узла дерева память должна выделяться динамически, поэтому худший случай не лучше, чем сортировка обменом.
Когда n случайных значений повторно вставляются в бинарное дерево поиска, можно ожидать, что дерево будет относительно сбалансированным. Наилучшим случаем является законченное бинарное дерево. Для этого случая можно оценить верхнюю границу, рассмотрев полное дерево глубиной d. На i-ом уровне (1?i?d) имеется 2i узлов. Поскольку для помещения узла на уровень i требуется i+1 сравнение, сортировка на полном дереве требует (i+1) * 2i сравнений для вставки всех элементов на уровень i. Если вспомнить, что n = 2(d+1) - 1, то верхняя граница меры эффективности выражается следующим неравенством:
Рис. 16.
Эффективность сортировки вставкой в дерево.
Ожидаемое число сравнений, необходимых для вставки узла в бинарное дерево поиска, равно O(log2n). Поскольку в дерево вставляется n элементов, средняя эффективность должна быть O(n log2n). Однако в худшем случае, когда исходный список отсортирован в обратном порядке, она составит O(n2). Соответствующее дерево поиска вырождается в связанный список. Покажем, что худший случай требует O(n2) сравнений. Первая вставка требует 0 сравнений. Вторая вставка – двух сравнений (одно с корнем и одно для определения того, в какое поддерево следует вставлять данное значение). Третья вставка требует трех сравнений, 4-я четырех,..., n-я вставка требует n сравнений. Тогда общее число сравнений равно:
0 + 2 + 3 + ... + n = (1 + 2 + 3 + ... + n) - 1 = n(n + 1) / 2 - 1 = O(n2)
Для каждого узла дерева память должна выделяться динамически, поэтому худший случай не лучше, чем сортировка обменом.
Когда n случайных значений повторно вставляются в бинарное дерево поиска, можно ожидать, что дерево будет относительно сбалансированным. Наилучшим случаем является законченное бинарное дерево. Для этого случая можно оценить верхнюю границу, рассмотрев полное дерево глубиной d. На i-ом уровне (1?i?d) имеется 2i узлов. Поскольку для помещения узла на уровень i требуется i+1 сравнение, сортировка на полном дереве требует (i+1) * 2i сравнений для вставки всех элементов на уровень i. Если вспомнить, что n = 2(d+1) - 1, то верхняя граница меры эффективности выражается следующим неравенством:
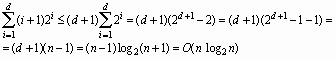 Таким образом, эффективность алгоритма в лучшем случае составит O(n log2n).
DelphiWorld 6.0
Таким образом, эффективность алгоритма в лучшем случае составит O(n log2n).
DelphiWorld 6.0
Отправить комментарий