Файловая система NTFS (статья)
Falk0ner, вс, 06/07/2008 - 15:34.
Для недопущения таких ситуаций система, желающая ограничиться логическим журналированием, вынуждена применять принцип "временно занятого места". Место, освобожденное каким-либо объектом или записью о нем, не объявляется свободным до тех пор, пока физически не завершились все операции с логическими структурами. Данный механизм в NTFS, по видимому, не синхронизирован даже с проставлением контрольных точек, так как типичное время освобождения временно занятого места - около 30 секунд, точки же идут чаще.
Данный механизм применяется не только при стирании файла, но и при самых разных операциях: принцип журналирования - объект, убранный или перемещенный на новое место, должен иметь возможность корректно откатить своё "отбытие" - то есть данные, на которые ссылаются логические структуры удаляемого или перемещаемого объекта, необходимо еще на некоторое время зарезервировать как занятое место (диска/каталога). Это еще один шаг NTFS к полному журналированию, где специфическим журналом файловой информации служат сами данные освобождаемых областей, не уничтожаемые физически.
Допущения, обеспечивающие надежность
Ну хорошо, скажете вы, всё так замечательно - но почему же тогда разделы NTFS всё же летят?.. Сейчас я постараюсь объяснить принципы, которые приводит к тому, что вышеописанная модель сможет обеспечить полную восстанавливаемость логических структур.·Жесткий диск, в штатном режиме, должен записать именно то и именно туда, что и куда ему сказано было записать операционной системой. Данный принцип нарушается в случае, если система имеет ненадежный шлейф, процессор, память или контроллер - и это самая распространенная причина сбоев NTFS. Вам поможет: неразогнанный процессор, дорогая (качественная) память, хорошая материнская плата и протокол UDMA, обеспечивающий контроль и восстановление ошибок на участке контроллер-диск. ·Жесткий диск, в случае аварии, отключения питания или получения от контроллера сигнала "сброс" (в случае внезапной перезагрузки материнской платы) обязан корректно завершить запись данных текущего физического сектора, если таковая производилась на момент аварии. Промежуточное состояние сектора не допускается. Вам помогут современные винчестеры, которые могут осуществить данную операцию даже в случае полного пропадания питания - у них хватит буферизированной в конденсаторах энергии, и их логика рассчитана на корректное поведение в случае отказа питания при записи. ·Диск обязан мгновенно осуществить запись данных, отправленных с флагом "не кэшировать". Дело в том, что многие современные диски или контроллеры обеспечивают задержанную запись. Метафайлы NTFS обновляются в режиме "писать сразу", и контроллер/диск обязан выполнять это требование. ·Жесткий диск обязан обеспечить чтение именно тех данных, которые были записаны. В случае невозможности прочесть данные выдается сигнал "ошибка". Диск не имеет права возвращать ошибочные данные (возможно, лишь частично некорректные) без сигнала об ошибке. Все современные жесткие диски имеют контрольные суммы секторов и жестко следуют этой логике поведения.
Четкое выполнение этих требований полностью гарантирует надежную работу NTFS. Структура файловой системы не будет содержать существенных ошибок даже после сбоя. Некоторые несущественные ошибки всё же появляются из-за того, что логика журналирования часто пытается завершить недоделанные операции - например, то же удаление файла - тогда как полную надежность обеспечивал бы только безусловный откат всего, что находится после последней контрольной точки. Малые несоответствия, рождающиеся из этих попыток, относятся к избыточной информации системы безопасности, не представляют никакой реальной опасности для данных - они действительно незначительны. Суть этих несоответствий чаще всего заключается в том, что на диске остаются "лишние" данные о тех режимах доступов, которые уже не понадобятся системе. Их прочистка - дело сугубо повышения производительности, как, например, дефрагментация, поэтому их наличие не является на самом деле ошибкой. В случае же обнаружения серьезных, реальных, проблем драйвер сам установит флажок тома "грязный", что проинструктирует систему проверить том при следующем его монтировании.
Я с большим сожалением должен сказать, что подавляющее большинство фатальных ошибок NTFS происходит по вине аппаратуры, не выполняющей эти элементарные требования. Да, я понимаю, абсолютной надежности не бывает. Но Microsoft пошел по пути разделения труда - за надежность вашей аппаратуры корпорация ответственности не несет. Мой компьютер на 70% не попадает в список совместимого с Windows 2000 оборудования, и то же самое можно сказать про почти любую реальную машину, функционирующую на просторах бывшего СССР. Особенно это относится к любителям разгонять компьютеры. Запомните раз и навсегда: вы с огромной степенью вероятности угробите NTFS в первый же год работы, если ваш процессор - 333, разогнанный на 415. И даже не раз... Мне очень жаль, но это действительно так. От любых сбоев корректного компьютера NTFS защитит, но вот от записи случайных данных в бут-сектор (копия которого, кстати, хранится в самом конце раздела) и в MFT система просто не страхуется. Извините.
Часть 5. Программный RAID
Журналирование NTFS, как уже указывалось ранее, ни в коей мере не гарантирует от сбоев с потерей пользовательской информации. Между тем, NT предлагает несколько вариантов создания систем, где, в разумных условиях, гарантируется абсолютно всё. Можно также использовать большее число дисков для обеспечения не повышенной надежности, а, наоборот, повышенной скорости - или того и другого одновременно. О таких конфигурациях и пойдет речь в этой части статьи.
RAID (Redundant Array of Inexpensive Disks) - избыточный массив недорогих дисков. Технология, заключающаяся в одновременном использовании нескольких дисковых устройств для обеспечения характеристик надежности или скорости, отсутствующих у накопителей в отдельности.
Windows NT поддерживает на программном уровне три уровня RAID (так называются стратегии работы дисковых массивов), краткие характеристики которых сведены в следующую таблицу.
Быстродействие, по сравнению с обычными дисками
Надежность
Общее дисковое пространство
RAID 0Параллельные дискиСущественное повышение производительности за счет дублирования дисков.
Теоретически, в условиях некоторых (например, линейных) операций скорость чтения/записи, повышается во столько раз, сколько дисков задействовано в системе.Реально увеличение быстродействия меньше - процентов 50%-90% от этого числа, что всё равно очень существенно.
Понижается - фатальный сбой одного из дисков вызовет потерю данных.
Равно сумме объемов составляющих массив дисков
RAID 1Зеркальные дискиПовышение надежности за счет дублирования информации.
Скорость чтения теоретически повышается в число раз, соответствующее числу дисков. Реализованный в NT алгоритм не оптимален и приводит к гораздо более скромному увеличению быстродействия.Скорость записи снижается, особенно в случае не до конца многозадачных дисковых контроллеров.
Потеря данных возможна лишь в случае отказа сразу всех дисков или повреждения одного и того же участка информации на всех дисках.
Остается неизменным (увеличение доступного дискового пространства за счет добавочных дисков не происходит).
RAID 5Параллельные диски с четностьюКомбинация RAID 1 и RAID 0 - более эффективное использование дополнительных дисков.
Скорость чтения повышается аналогичным RAID 0 образом, но число дисков, влияющих на быстродействие, следует уменьшить на один. Т.е. три диска RAID 5 обладают примерно такой же скоростью чтения, как и два диска RAID 0.Скорость записи больше, чем у каждого диска в отдельности, но в целом невысока.
Потеря данных возможна при выходе из строя двух дисков набора. Выход из строя одного из дисков существенно снижает скорость работы всего массива и является, по сути, аварийной ситуацией, хоть и без потери данных.
Увеличивается.Потеря от суммарного дискового объема составляет объем одного диска.Например, пять дисков по 10 Гб дают RAID 5 объемом 40 Гб.
Остановимся подробнее на каждом из типов RAID-а.
RAID 0 (параллельные диски)
Данная стратегия направлена исключительно на повышение производительности. Несколько дисков хранят части дисковой структуры, которые собираются в один том лишь при наличии всех дисков массива.
Простейшая реализация RAID 0 из двух, например, дисков - указание на то, что каждый первый сектор тома (или любой другой объем информации) расположен на физическом диске A, а каждый второй - на диске B. Такая жесткая стратегия дает возможность избежать каких-либо дополнительных структур для хранения информации о том, где находятся какие данные. Скорость чтения, как и записи равны и зависят от числа дисков:·Быстродействие операции по работе со случайно расположенными данными подчиняются следующей схеме: всё зависит от вероятности того, что диск, на который мы хотим записать очередную порцию информации, свободен и готов мгновенно выполнить наш запрос. Например, RAID 0 из двух дисков: при осуществлении операции одним из дисков и поступлении дополнительной команды на работу с дисковой системой вероятность того, что для выполнения команды нам придется тревожить свободный в данный момент диск составляет 50% - это соответствует общему увеличению производительности случайных операций в полтора раза. Если же используется, к примеру, массив из десяти дисков, то вероятность какой-либо операции попасть на уже занятый накопитель составляет всего 10% - то есть производительность повышается в девять раз. Любителям строгой теории вероятности хочу заметить, что при таких подсчетах не учитываются некоторые факторы реальной работы систем, но цифры, тем не менее, имеют именно такой порядок. ·Последовательные операции - чтение или запись последовательных участков - проходят практически всегда в n раз быстрее, чем на отдельном физическом диске, где n - число дисков в наборе. Это происходит потому, что вероятность в следующей операции попасть на свободный диск составляет 100% - ведь операции осуществляются последовательными блоками, которые равномерно раскидываются по дискам.
В качестве некоторого вывода - RAID 0 в любом случае существенно повышает быстродействие линейных операций, а с увеличением количества дисков, входящих в набор, существенно повышается скорость работы и со случайными данными. Для эффективной работы с дисковой системой в режиме RAID 0 просто необходим многозадачный режим работы контроллера, а желательно даже разных контроллеров, обеспечивающих доступ к разным дискам. Обязательным условием такой работы на интерфейсах IDE являются Bus-Mastering драйвера. Windows 2000 имеет встроенные драйвера, автоматически включающие этот режим для всех распространенных IDE контроллеров, для NT4 же могут понадобится дополнительные драйвера или изменения ключей реестра.
Надежность RAID 0 низка - отказ каждого диска является фатальным сбоем, точно так же, как и отказ накопителя в случае работы с обычными разделами.
Вероятность сбоя системы в целом только повышается - чем больше дисков вы используете, тем выше вероятность отказа хоть одного из них и, соответственно, потери какой-то части данных тома.
RAID 1 (зеркальные диски)
Самый простой способ обеспечения безопасности данных - создать копию двух дисков. Запись осуществляется на оба диска сразу, что приводит к замедлению этого процесса, тогда как чтение - с того диска, который в данный момент свободен - если, конечно, система способна эффективно осуществить такое чтение (необходимо наличие Bus-Mastering). Реализованный в NT алгоритм, к сожалению, не совсем оптимален и приводит к гораздо более скромному увеличению быстродействия чтения.
Некоторая сложность работы RAID 1 в программном режиме заключается в том, что часто система не может быть до конца уверена в идентичности данных двух дисков. Операция сверки двух физических дисков после серьезного сбоя может затянутся на часы и быть очень некстати, поэтому использовать программный RAID 1 следует очень осмотрительно. Если вы решаетесь на увеличение дисковых массивов в несколько раз только ради надежности, возможно, вам стоит приобрести аппаратный RAID контроллер, который, к тому же, обеспечит замену вышедших из строя дисков прямо на ходу и будет следить за синхронностью данных сам.
В любом случае, даже полный отказ одного из дисков не приводит к потере данных, так как диски полностью зеркальны.
RAID 5 (параллельные диски с четностью)
Данная стратегия представляется в настоящее время наиболее удачной и эффективной схемой работы RAID, состоящих из трех и более дисков. Информация дополняется так называемыми данными четности (parity), которые размещаются на другом физическом диске, нежели реальные данные, контролируемые этой информацией.
Концепцию четности можно понять, например, так: допустим, у нас есть пять бит - например, набор {0, 1, 1, 0, 1}. Мы формируем еще бит - бит четности, шестой, по такому правилу - если число единиц в предыдущих пяти битах четно, он будет равен 1, если нет - 0. В нашем случае число единиц равняется трем, т.е. нечетному числу - наш набор дополнился числом 0 и превратился в {0, 1, 1, 0, 1, <0>}.
Допустим, набору данных причинен урон - {0, X, 1, 0, 1, <0>}. С помощью правила, гласящего нам, что число единиц должно быть нечетно (последний бит), мы можем догадаться, что на месте X стояла единичка. Наш получившийся набор из шести бит (5 бит данных и 1 бит четности) избыточен и может грамотно скорректировать потерю любого из своих шести бит.
Операции четности могут осуществляться не только с битами, но и с любыми объемами данных, что применяется в простейших алгоритмах восстановления данных.
Возвращаемся к устройству RAID 5:
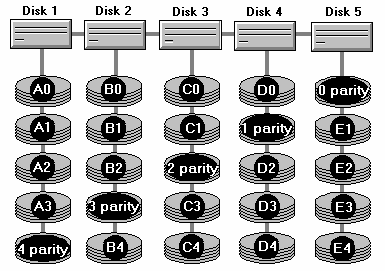 На рисунке изображен массив из пяти дисков. Видно, что каждый диск хранит четыре (условные) части реальных данных и один блок данных четности. Блок четности - скажем, 0 parity - способен восстановить потерю одного из фрагментов - любого, но одного - среди A0, B0, C0 и D0. Все вместе они, в свою очередь, способны восстановить блок 0 parity. Из изображенной структуры RAID видно, что данные, необходимые для полного восстановления всего столбика - то есть информации любого диска в случае сбоя - находятся на других дисках. В этом и заключается восстановление - при записи данных на любой из дисков обновляется также блок четности другого диска, соответствующего текущему блоку (например, при записи в A2 обновляется еще и блок 2 parity). Чтение данных с исправного диска происходит без использования блоков четности, т.е. почти в том же режиме, в каком работает RAID 0. Быстродействие RAID 5 в том виде, в каком это реализовано в NT, даже немного выше, чем у RAID 0.
Единственная накладка - в случае сбоя производительность массива снижается в огромное количество раз, так как при невозможности напрямую считать, например, D4, нужно будет восстанавливать данные этого блока с использованием всех других дисков одновременно - в нашем случае это будут блоки 4 parity, B4, C4 и E4.
Как видно, выход из строя одного из дисков RAID 5 является хоть и не фатальной, но резко аварийной ситуацией - хотя бы из соображений быстродействия чтения с массива. Нетрудно догадаться также, откуда исходит требования как минимум трех дисков - в случае двух накопителей RAID 5 просто вырождается в RAID 1, так как единственный способ создать информацию четности списка из одного элемента - это тем или иным образом дублировать этот элемент.
На рисунке изображен массив из пяти дисков. Видно, что каждый диск хранит четыре (условные) части реальных данных и один блок данных четности. Блок четности - скажем, 0 parity - способен восстановить потерю одного из фрагментов - любого, но одного - среди A0, B0, C0 и D0. Все вместе они, в свою очередь, способны восстановить блок 0 parity. Из изображенной структуры RAID видно, что данные, необходимые для полного восстановления всего столбика - то есть информации любого диска в случае сбоя - находятся на других дисках. В этом и заключается восстановление - при записи данных на любой из дисков обновляется также блок четности другого диска, соответствующего текущему блоку (например, при записи в A2 обновляется еще и блок 2 parity). Чтение данных с исправного диска происходит без использования блоков четности, т.е. почти в том же режиме, в каком работает RAID 0. Быстродействие RAID 5 в том виде, в каком это реализовано в NT, даже немного выше, чем у RAID 0.
Единственная накладка - в случае сбоя производительность массива снижается в огромное количество раз, так как при невозможности напрямую считать, например, D4, нужно будет восстанавливать данные этого блока с использованием всех других дисков одновременно - в нашем случае это будут блоки 4 parity, B4, C4 и E4.
Как видно, выход из строя одного из дисков RAID 5 является хоть и не фатальной, но резко аварийной ситуацией - хотя бы из соображений быстродействия чтения с массива. Нетрудно догадаться также, откуда исходит требования как минимум трех дисков - в случае двух накопителей RAID 5 просто вырождается в RAID 1, так как единственный способ создать информацию четности списка из одного элемента - это тем или иным образом дублировать этот элемент.
Отправить комментарий