Объектно-ориентированный подход и современные мониторы транзакций
Falk0ner, вс, 06/07/2008 - 15:34.
Объектно-ориентированный подход и современные мониторы транзакций
Объектно-ориентированный подход и современные мониторы транзакций
В. Индриков, АО ВЕСТЬ
Объектно-ориентированный подход и мониторы транзакций? А где, собственно, связь? Если с ООП все, вроде бы, ясно, то мониторы - вопрос темный, да и, кажется, вообще из другой области. Зачем они вообще? "А затем," - отвечают нам, - "чтобы обеспечить высокую пропускную способность системы и повышает ее устойчивость к сбоям." "Помилуйте," - локтем отодвигает предыдущего оратора создатель сервера баз данных, - "мы это и без них прекрасно умеем - и на кластерах работаем, и транзакции мониторим." Тут вам и диспут, и острота схватки. Говорят и такое: "Многие ..., кто ... выбирает мониторы транзакций, применяет их не по назначению. Не так часто мониторы транзакций используются ради того, для чего они и предназначены, конкретно - поддержки сотен или тысяч одновременно работающих пользователей - такие внедрения составляют не более 1% рынка. Все остальные примеры свидетельствуют о том, что мониторы занимаются асинхронной передачей сообщений или играют роль связующего программного обеспечения в разнородных средах." (DATABASE Journal, N2 1996 стр. 77, перевод мой).
В этом изречении содержится, как минимум, две мысли. Первая - есть альтернативы мониторам транзакций. Вторая, спорная - мониторы предназначены для обработки тысяч транзакций на одной системе и ничего более. Самое забавное, что и те, кто продает мониторы, чаще всего думают также. И спорю с ними не я, а как раз те, кто применяет эти мониторы, и, если верить тексту, 99% пользователей использует их отнюдь не ради тех возможностей, которые "и так присутствуют в серверах БД." Я даже позволю себе предположить, что они, пользователи, нуждаются в мониторе транзакций, поскольку тот является средой разработки распределенных приложений. Средой, которая, очевидно, имеет какие-то плюсы.
И я даже готов был бы согласиться с тем, что среда эта не является объектно-ориентированной, если бы не обратившее на себя внимание пугающее сходство CSI (Client/Server Interactions) диаграмм в документации на монитор End и диаграмм сценариев в объектно-ориентированных методах Буча и Fusion. Речь не о принципиальном сходстве, это полбеды, а об изобразительном - повернув CSI на девяносто градусов против часовой стрелки, вы не найдете разницы, обозначения убийственно идентичны.
Причина в том, что, как только разговор выходит за рамки отношений между классами, а точнее, единственного, пожалуй, рассматриваемого в них вида отношений (наследования), большинство из ныне здравствующих ОО методов (почему-то их постоянно пытаются называть методологиями) предлагают набор изобразительных средств, существенно превосходящий по возрасту ОО подход - сценарии и диаграммы перехода состояний, анализ доменов и т.д. Причем в 3 из 5 случаев оказывается, что наследование существует само по себе, а все остальное - в стороне. Блистательным, с моей точки зрения, примером конгломерата из слабо связанных между собой подходов является метод Гради Буча. Наследование объявляется ключом к объектно-ориентированному подходу, все остальное - "недоразвитым", объектно-базирующимся подходом (вот вам еще одна загадка - что лучше, базироваться на объектах или ориентироваться на них?), и в то же самое время Рамбо (метод OMT) является одним из немногих, кому пришла в голову нестандартная мысль - сценарии и диаграммы перехода суперкласса должны наследоваться в подклассах. Между тем, даже и в этом случае мы далеки от разрешения всех проблем - имеет место эффект расщепления состояния в подклассе (state partitioning - S.Matsuoka, K.Wakita, A.Yonezawa, Inheritance Anomaly in Object-Oriented Concurrent Languages, University of Tokyo, 1991), заставляющий переопределять методы суперкласса. Одной из причин является то, что само понятие "состояние" никак не определяется, поэтому, что означает "унаследовать состояние" или "унаследовать переход", остается за рамками ОО метода. Да и само по себе наследование суть целый букет проблем: self проблема, конфликт с требованием атомарности операций, переписывание (overriding) методов по принципу "все или ничего" вместо декларированного в ООП "уточнения", трудности с интеграцией с СУБД, трудности в реализации множественных представлений (views) и координированного выполнения и т.д. (см, например, M.Askit, M.Bergmans Obstacles in Object-Oriented Development, TRESE Project, University of Twente; H. Lieberman, Using Prototypical Objects to implement shared behavior, OOPSLA '86).
Илл. 1
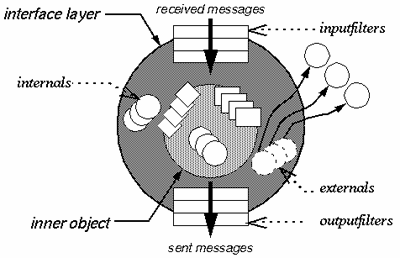
Крайне интересной попыткой разрешить многие из трудностей с реализацией наследования и на деле позволить применять ООП в больших программных проектах (programming in large), является модель CFOM (Composition-Filters Object Model), разрабатываемая в Университете Твенте, Нидерланды. Она доводит до кристальной чистоты старую идею, гласящую, что сообщения, передаваемые объекту, и методы, обрабатывающие эти сообщения - не обязательно одно и то же, а сообщение представляет самостоятельный интерес. CFOM разводит объект-ядро (kernel object) и интерфейс. Объект-ядро полностью инкапсулирован, его структура недоступна извне, открыты только методы, но и те - не для всех, а только для интерфейса, являющегося своего рода оболочкой объекта. Интерфейс может содержать объекты (секция internals) или ссылки на внешние объекты (externals), а также фильтры. Фильтры задают правила обработки входящих (inputfilters) и, мало того - исходящих (outputfilters) сообщений (Ошибка! Источник ссылки не найден.). В простейшем случае сообщение передается ядру на выполнение, и выглядит это так: inner.doSmth. Inner - это и есть ядро. В общем же случае сообщение, попав в сито фильтров, может быть также модифицировано либо переадресовано одному из объектов, определенных в теле интерфейса, или внешним объектам.
Модель CFOM смело можно отнести к числу "недоразвитых" - вводя понятие объекта и класса, ее создатели отказались от введения отношений наследования. Сделано это по причинам, кратко уже упомянутым выше, и развернутое описание которых займет слишком много места. Каким же образом создатели CFOM ухитряются обойтись без наследования? Очень просто - включение и делегирование. Если вы хотите, чтобы объект objA класса A предоставлял и сервис класса B, вы включаете объект objB класса B в секцию internals интерфейса и помимо возможных прочих фильтров указываете такой: {inner.*, objB.*}. Понять, что делает этот фильтр, легко - все сообщения ('*' и означает "все"), распознаваемые ядром, передавать ядру, все сообщения, распознаваемые объектом objB (т.е. все сообщения класса B), передавать objB. С печально известными проблемами множественного наследования здесь сталкиваться не приходится - фильтры выполняются слева направо и сверху вниз. Если набор методы A и B пересекаются, и вы хотите, чтобы сообщение mess1 обрабатывалось в B, а не в A, то фильтр становится таким: {objB.mess1, inner.*, objB.*}. Если objB объявлен в секции externals, то это ссылка на внешний объект, и в этом случае фильтр {..., objB.*, ...} будет реализовывать делегирование в чистом виде.
На самом деле синтаксис фильтров несколько более сложен, и важную роль играют здесь условия (conditions) - особая группа методов ядра, не имеющих параметров и вырабатывающих значение булевского типа. Тот или иной фильтр может срабатывать или быть проигнорирован в зависимости от условий. Введение условий позволяет в рамках одной модели описать и переходы состояний - изменение состояния объекта и даже история изменения состояний объекта может находить свое отражение в изменении условиях, а те будут задавать тот или иной сценарий обработки сообщений. Введены также псевдопеременные: sender (№1 на Илл. 2) - идентифицирует объект, пославший сообщение; упоминавшаяся уже inner (№4 на Илл. 2) - ядро, т.е. собственно реализация той или иной совокупности сервисов; self - означает то же самое, что и self в Samlltalk или this в C++ - ссылка на сам объект в теле программного кода, принадлежащего этому объекту; message (№5) - метаданные, т.е. имя сообщения и список аргументов; server (№2) - объект, который первым принял сообщение. В приведенном выше примере сервером является объект objA. Если бы objA в свою очередь был бы включен в интерфейсную часть объекта objX (неважно, где бы он был объявлен - в секции internals или externals), то сервером стал бы objX. Сообщение, проходя через множество фильтров, может много раз поменять "направление", однако значение server не изменится. Данная псевдопеременная помогает объекту разобраться, в каком контекcте он получает сообщение. Например, public и private, реализованные в C++, легко воспроизводятся с использованием server.

Илл.
Отправить комментарий