AVL-деревья
Falk0ner, вс, 06/07/2008 - 15:35.
Двойной поворот иллюстрируется на дереве, изображенном на рисунке 13. Попытка вставить узел 25 разбалансирует корневой узел 50. В этом случае узел 20 (LC) приобретает слишком высокое правое поддерево и требуется двойной поворот. Новым родительским узлом (NP) становится узел 40. Старый родительский узел становится его правым сыном и присоединяет к себе узел 45, который также переходит с левой стороны дерева.
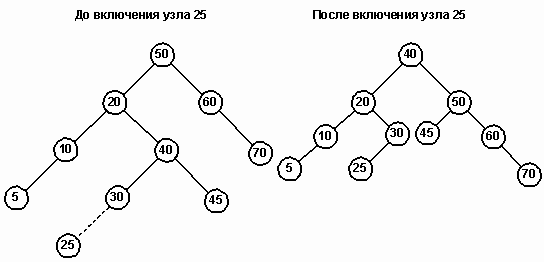 Рис. 13.
Оценка сбалансированных деревьев
Обоснованность применения AVL-деревьев неоднозначна, поскольку они требуют дополнительных затрат на поддержание сбалансированности при вставке или удалении узлов. Если в дереве постоянно происходят вставки и удаления элементов, эти операции могут значительно снизить быстродействие. С другой стороны, если ваши данные превращают бинарное дерево поиска в вырожденное, вы теряете поисковую эффективность и вынуждены использовать AVL-дерево. В большинстве случаев в программах используются алгоритмы, когда сначала заполняется список, а потом производится поиск по этому списку с небольшим количеством изменений. Поэтому на практике использование AVL-деревьев предпочтительно.
Для AVL-дерева не существует наихудшего случая, так как оно является почти полным бинарным деревом. Сложность операции поиска составляет O(log2n). Опыт показывает, что повороты требуются примерно в половине случаев вставок и удалений. Сложность балансировки обусловливает применение AVL-деревьев только там, где поиск является доминирующей операцией.
Оценка производительности AVL-деревьев
Эта программа сравнивает сбалансированное и обычное бинарные деревья поиска, каждое из которых содержит N случайных чисел. Исходные данные для этих деревьев берутся из единого массива. Для каждого элемента массива осуществляется его поиск в обоих деревьях. Длины поисковых путей суммируются, а затем подсчитывается средняя длина поиска по каждому дереву.
Программа прогоняется на 1000- и на 10000-элементном массивах. Обратите внимание, что на случайных данных поисковые характеристики AVL-дерева несколько лучше. В самом худшем случае вырожденное дерево поиска, содержащее 1000 элементов, имеет среднюю глубину 500, в то время как средняя глубина AVL-дерева всегда равна 9.
Рис. 13.
Оценка сбалансированных деревьев
Обоснованность применения AVL-деревьев неоднозначна, поскольку они требуют дополнительных затрат на поддержание сбалансированности при вставке или удалении узлов. Если в дереве постоянно происходят вставки и удаления элементов, эти операции могут значительно снизить быстродействие. С другой стороны, если ваши данные превращают бинарное дерево поиска в вырожденное, вы теряете поисковую эффективность и вынуждены использовать AVL-дерево. В большинстве случаев в программах используются алгоритмы, когда сначала заполняется список, а потом производится поиск по этому списку с небольшим количеством изменений. Поэтому на практике использование AVL-деревьев предпочтительно.
Для AVL-дерева не существует наихудшего случая, так как оно является почти полным бинарным деревом. Сложность операции поиска составляет O(log2n). Опыт показывает, что повороты требуются примерно в половине случаев вставок и удалений. Сложность балансировки обусловливает применение AVL-деревьев только там, где поиск является доминирующей операцией.
Оценка производительности AVL-деревьев
Эта программа сравнивает сбалансированное и обычное бинарные деревья поиска, каждое из которых содержит N случайных чисел. Исходные данные для этих деревьев берутся из единого массива. Для каждого элемента массива осуществляется его поиск в обоих деревьях. Длины поисковых путей суммируются, а затем подсчитывается средняя длина поиска по каждому дереву.
Программа прогоняется на 1000- и на 10000-элементном массивах. Обратите внимание, что на случайных данных поисковые характеристики AVL-дерева несколько лучше. В самом худшем случае вырожденное дерево поиска, содержащее 1000 элементов, имеет среднюю глубину 500, в то время как средняя глубина AVL-дерева всегда равна 9.
#0include < iostream.h >
#0include "bstree.h"
#0include "avltree.h"
#0include "random.h"
// загрузить из массива числа в бинарное поисковое дерево и AVL-дерево
void SetupLists(BinSTree < int > Tree1, AVLTree < int > Tree2, int A[], int n)
{
int i;
RandomNumber rnd;
// запомнить случайное число в массиве А, а также вставить его
// в бинарное дерево поиска и в AVL-дерево
for (i=0; i<n; i++)
{
A[i] = rnd.Random(1000);
Tree1.Insert(A[i]);
Tree2.Insert(A[i]);
}
}
// поиск элемента item в дереве t.
// При этом накапливается суммарная длина поиска.
template < class T >
void PathLength(TreeNode < T > * t, long totallength, int item)
{
// возврат, если элемент найден или отсутствует в списке
if (t == NULL || t->data == item)
return;
else
{
// перейти на следующий уровень. Увеличить суммарную длину пути поиска.
totallength++;
if (item < t->data)
PathLength(t->Left(), totallength, item);
else
PathLength(t->Right(), totallength, item);
}
}
void main(void);
{
// переменные для деревьев и массива
BinSTree<int> binTree;
AVLTree<int> avlTree;
int *A;
// суммарные длины поисковых путей элементов
// массива в бинарном дереве поиска
// и в AVL-дереве
long totalLengthBintree = 0, totalLengthAVLTree = 0;
int n, i;
cout << "Сколько узлов на дереве? ";
cin >> n;
// загрузить случайными числами массив и оба дерева
SetupLists(binTree, avlTree, A, n);
for (i=0; i<n; i++)
{
PathLength(binTree.GetRoot(), totalLengthBintree, A[i]);
PathLength((TreeNode<int> *)avlTree.getRoot(),
totalLengthAVLTree, A[i]);
}
cout < < "Средняя длина поиска для бинарного дерева = "
< < float(totalLengthBintree) / n < < endl;
cout < < "Средняя длина поиска для сбалансированного дерева = "
< < float(totalLengthAVLTree) / n < < endl;
}
#0include "bstree.h"
#0include "avltree.h"
#0include "random.h"
// загрузить из массива числа в бинарное поисковое дерево и AVL-дерево
void SetupLists(BinSTree < int > Tree1, AVLTree < int > Tree2, int A[], int n)
{
int i;
RandomNumber rnd;
// запомнить случайное число в массиве А, а также вставить его
// в бинарное дерево поиска и в AVL-дерево
for (i=0; i<n; i++)
{
A[i] = rnd.Random(1000);
Tree1.Insert(A[i]);
Tree2.Insert(A[i]);
}
}
// поиск элемента item в дереве t.
// При этом накапливается суммарная длина поиска.
template < class T >
void PathLength(TreeNode < T > * t, long totallength, int item)
{
// возврат, если элемент найден или отсутствует в списке
if (t == NULL || t->data == item)
return;
else
{
// перейти на следующий уровень. Увеличить суммарную длину пути поиска.
totallength++;
if (item < t->data)
PathLength(t->Left(), totallength, item);
else
PathLength(t->Right(), totallength, item);
}
}
void main(void);
{
// переменные для деревьев и массива
BinSTree<int> binTree;
AVLTree<int> avlTree;
int *A;
// суммарные длины поисковых путей элементов
// массива в бинарном дереве поиска
// и в AVL-дереве
long totalLengthBintree = 0, totalLengthAVLTree = 0;
int n, i;
cout << "Сколько узлов на дереве? ";
cin >> n;
// загрузить случайными числами массив и оба дерева
SetupLists(binTree, avlTree, A, n);
for (i=0; i<n; i++)
{
PathLength(binTree.GetRoot(), totalLengthBintree, A[i]);
PathLength((TreeNode<int> *)avlTree.getRoot(),
totalLengthAVLTree, A[i]);
}
cout < < "Средняя длина поиска для бинарного дерева = "
< < float(totalLengthBintree) / n < < endl;
cout < < "Средняя длина поиска для сбалансированного дерева = "
< < float(totalLengthAVLTree) / n < < endl;
}
Прогон 1:
Сколько узлов на дереве? 1000Средняя длина поиска для бинарного дерева = 10.256Средняя длина поиска для сбалансированного дерева = 7.901
Прогон 2:
Сколько узлов на дереве? 10000Средняя длина поиска для бинарного дерева = 12.2822Средняя длина поиска для сбалансированного дерева = 8.5632Итераторы деревьев
Сканирование узлов дерева более сложно, чем сканирование массивов и последовательных списков, так как дерево является нелинейной структурой и существует несколько способов прохождения дерева. Мы уже разбирали эти способы выше. Проблема каждого из них состоит в том, что до завершения рекурсивного процесса из него невозможно выйти. Нельзя остановить сканирование, проверить содержимое узла, выполнить какие-нибудь операции с данными, а затем вновь продолжить сканирование со следующего узла дерева. Используя же итератор, клиент получает средство сканирования узлов дерева, как если бы они представляли собой линейный список, без обременительных деталей алгоритмов прохождения, лежащих в основе процесса.
Наш класс использует класс Stack и наследуется от базового класса итератора. Поэтому сначала опишем класс Stack и базовый класс итератора.
Спецификация класса Stack
Объявление
#0include < iostreani.h >
#0include < stdlib.h >
const
int MaxStackSize = 50;
class Stack
{
private:
DataType stacklist[MaxStackSize];
int top;
public:
// конструктор; инициализирует вершину
Stack(void);
// операции модификации стека
void Push(const DataType item);
DataType Pop(void);
void ClearStack(void);
// доступ к стеку
DataType Peek(void) const;
// методы проверки состояния стека
int StackEmpty(void) const;
int StackFull(void) const; // для реализации, основанной на массиве
};
#0include < stdlib.h >
const
int MaxStackSize = 50;
class Stack
{
private:
DataType stacklist[MaxStackSize];
int top;
public:
// конструктор; инициализирует вершину
Stack(void);
// операции модификации стека
void Push(const DataType item);
DataType Pop(void);
void ClearStack(void);
// доступ к стеку
DataType Peek(void) const;
// методы проверки состояния стека
int StackEmpty(void) const;
int StackFull(void) const; // для реализации, основанной на массиве
};
Описание
Данные в стеке имеют тип DataType, который должен определяться с использованием оператора typedef. Пользователь должен проверять, полный ли стек, перед попыткой поместить в него элемент и проверять, не пустой ли стек, перед извлечением данных из него. Если предусловия для операции push или pop не удовлетворяются, печатается сообщение об ошибке и программа завершается.
StackEmpty возвращает TRUE, если стек пустой, и FALSE — в противном случае. Используйте StackEmpty, чтобы определить, может ли выполняться операция Pop.
StackFull возвращает TRUE, если стек полный, и FALSE — в противном случае. Используйте StackFull, чтобы определить, может ли выполняться операция Push.
ClearStack делает стек пустым, устанавливая top = -1. Этот метод позволяет использовать стек для других целей.
Реализация класса Stack
Конструктор Stack присваивает индексу top значение -1, что эквивалентно условию пустого стека.
//инициализация вершины стека
Stack: : Stack(void): top(-l)
{ }
Операции стека.
Две основные операции стека вставляют (Push) и удаляют (Pop) элемент из стека. Класс содержит функцию Peek, позволяющую получать данные элемента, находящегося в вершине стека, не удаляя в действит&;#1077;льности этот элемент.
При помещении элемента в стек, top увеличивается на 1, и новый элемент вставляется в конец массива stacklist. Попытка добавить элемент в полный стек приведет к сообщению об ошибке и завершению программы.
Отправить комментарий